By ADMIN
nginx ncache performance and stability
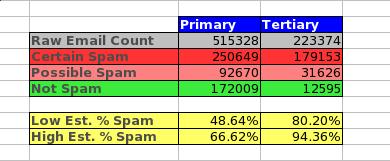
BACKGROUND: We’ve been running nginx successfully for a long long time now without issue. We were really pleased with it, and migrated all of our CDN servers across to using it several months ago. While there were a few little configuration defaults that didn’t play too nicely, we ironed out the problems within a few days and it’s business as usual, serving between 700TB and 1.8PB (In August 2008!) per month!
Now we have the problem that our proprietary systems that actually cache our customer’s sites just aren’t fast enough to handle the fast-changing content that our customers are demanding. So we’ve been weighing up a few options:
1) Deploy Varnish
2) Deploy Squid
3) Deploy ncache
We actually TRIED to deply varnish after seeing so many recommendations, but at the end of the day it couldn’t keep up. It really should be noted that our systems are all 32bit, and I get the feeling varnish would perform a lot better on 64bit, but when you have over a hundred servers all running on 32bit processors…..upgrading them all in one hit just isn’t an option. The problem with varnish is that it would drop connections seemingly because it had run out of memory (although we’re not 100% on this as the debugging wasn’t overly useful).
So…..we tried……we failed. NEXT
Our next attempt was to look into deploying Squid. This one proved a bit complex to integrate into our existing CDN network because of squid’s limitations. We would have to write a bit of custom code to make this one work, so it has been made a last resort.
So, option 3 (which is the whole point of this blog entry), was to try out the ncache nginx module. So we installed the ncache 2.0 package along with nginx 0.6.32. We set them all up and things ran absolutely beautifully. We manually tested caches and it was working great, very fast, very efficient, and well, it was great!
We were extremely happy until the next day when one CDN started reporting high load issues. In analysing the server, it seems nginx was trying to consume several gig of memory – owch. So we killed it off and restarted it, and it ran fine again. Maybe it was just a temporary glitch?
Nope – over the following week, we had several servers experience identical issues – that is, where nginx consumes all available memory until such a point that it simply stops being able to serve files and requires a restart. Looks like a case of either:
A) ncache 2.0 has a serious memory leak
B) ncache 2.0 doesn’t handle high volumes of cached data very well.
We’ve tried to work through the issues to make sure they’re not configuration issues, but no luck. At the end of the day it’s going to be cheaper and easier to make some mods to squid and deply that instead.
So for anybody wondering about ncache performance and stability, I’d simply say that it’s a great product, but not really production-ready at this stage if you’re doing high volumes of data.